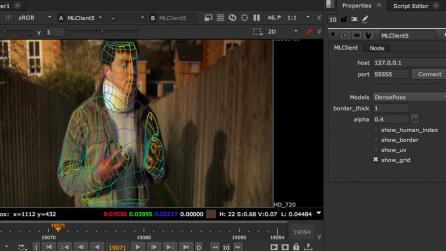
Machine learning in VFX software: the challenges to crack
Machine learning (ML) is one of the most exciting areas of technology under research today.
The promise of automating many laborious, time-consuming tasks currently performed by humans has caught the attention of a whole spectrum of industries.
For the VFX industry, getting efficient ML tools into the hands of artists could be transformational - both in terms of workflow for creatives and the bottom line for studios.
Foundry is currently leading a research project named SmartROTO - in partnership with pioneering VFX studio DNEG and the University of Bath (UoB) - which aims to develop intelligent tools for high-end rotoscoping of live action footage, and investigate the sharing of ML networks and datasets.
In this article, we’ll take a look at some of the challenges this project is trying to solve.
Machine-centric to data-centric
The way we think about creating visual computing algorithms has come on leaps and bounds.
Modern machine learning has shifted the focus from a machine-centric approach to a data-centric one.
Instead of focusing on testing and optimizing the tool itself, today the data used to train the tool is center stage. The success and performance of the tool is almost entirely dependent on the quality, diversity and size of this data set.
For companies that create visual effects software - and the post-houses that are their clients - this new, data-driven environment presents a number of hurdles to be negotiated.
Deploying ML tools in VFX pipelines
Currently, deploying effective machine learning tools into VFX pipelines can be tricky.
ML tools deployed via cloud or web can be released into the wild, used, and start gathering user data which can be acted upon to improve the tool pretty much immediately.
In contrast, traditional VFX software release cycles, with their relatively lengthy gaps in between updates, mean that improvements to ML models are few and far between.
Effectively, software developers become a bottleneck: gate-keepers of what technology makes it into the next version, with long delays between idea and release. The most efficient scenario would be one in which studios could update and improve ML models directly themselves: rather than waiting for software vendors to release updates.
Beyond this, an even bigger challenge is the interactivity of the ML networks you can deploy.
Most ML networks that can be deployed natively into a VFX pipeline work in a way in which information always moves in one direction - forwards. It never goes backwards.
That means that in the majority of these ML pipelines, the system can't learn on the fly. For example, if the network performs a task (like assisting with rotoscoping), and the artist notices and corrects some small errors the system has made, that corrective information can’t be fed back so that the system learns from its mistakes.
This severely limits interactivity between the network and the artist. If the system isn’t cyclical, there’s no opportunity for transfer or reinforcement learning of the network, or for further training it online.
And because this feedback isn’t available, you lose one of the key pillars of machine learning: live, ground-truth data which could be used to refine the model.
A third significant deployment hurdle to overcome is around cost. Machine learning models can use up huge amount of GPU memory during the inference phase of the process, during which the system is taking its learnt knowledge and applying that to identify things from previously unseen data.
If you take the network from a research context and put it into a VFX production one (like trying to infer from 4K plates), the GPU memory requirement can rise further still.
This has budgetary implications for studios: it might not be cost-effective to kit out every artist with a powerful GPU - especially just to facilitate one or two ML-assisted tasks.
Physically deploying efficient and workable ML tools into a VFX pipeline is therefore the first big hurdle to overcome if the industry is to see widespread benefits from machine learning research. 
The big data-sharing and IP issue
In machine learning, the quality of your results is dependent on the amount, diversity and quality of the data your system is trained on.
Data is incredibly valuable in every industry. Advertising data and consumer spending habits is powerful, actionable information, for example.
However, data is of no use on its own: it has to be processed and analyzed. Something has to be done with it.
In the VFX industry, the reasons studios might share their data could be anything from improving a software vendor’s tools to better fit their needs, to servicing an agreement with a sister business.
In practice, strict Intellectual Property (IP) agreements usually make sharing difficult. There’s a significant challenge around how to enable sharing while being respectful of IP.
This challenge is broad enough to merit its own book, but two of the big points worth looking at are federated learning and representation learning.
Traditional machine learning uses a centralized approach, in which all the training data used to train your ML model is aggregated on a single machine or data center.
This ‘all-your-eggs-in-one-basket’ scenario is problematic for the IP owners of films, who are worried about imagery from the huge, multi-billion dollar production they’ve been working on for 10 years getting leaked.
Federated learning is an alternative method, in which the training of the ML model is done locally, and the improved model is sent to the central server (rather than the training data itself).
The central server can aggregate the results of multiple users, and feed back an improved model based on everybody’s results. Effectively this means that the IP (the training data) doesn’t get shared - just the results do.
Federated learning could be an answer to the data-sharing issue then, except that it suffers from some flaws around scalability: essentially, if too many people upload too few data samples, the model can become skewed.
Another viable approach to share IP-protected data resides in representation learning.
Representation learning is about bringing order to chaos, by better understanding the characteristics of data in order to work out what something is.
On a basic level, for example, if an algorithm was trying to pick out a triangle from a row of shapes, it could use the number of corners as an indicator.
Representation learning detangles the different layers of a neural network and labels everything up, so it’s easy to understand.
For the VFX industry, the exact opposite could be valuable: tangling up the layers so they are indecipherable. This could serve as a form of encryption, making it possible to get a result that a) makes it impossible to reverse engineer the original image from its layer outputs, but b) still contains information useful for the given tasks.
Let’s say a studio wants to help improve an ML model, but is using sensitive, IP-protected imagery of a particular character.
Rather than sending the image directly to their partner software vendor or studio, they run it through the encryption layer stack.
The partner studio receives everything they need to improve the ML model, but no comprehensible data that reveals what the original training imagery was.
The importance of artist participation
A further big challenge to overcome lies in building a bridge between the artist and the algorithm.
Film production is naturally collaborative in nature, with thousands of staff working together to complete a show.
In contrast, machine learning is something of a solo pursuit, with an algorithm aiming to solve an entire problem in one go on its own, removing artists from the creative or technical process.
For artists to ever buy-in to machine learning tools, they need to be developed in a way which includes artist input. This isn’t only necessary for placating artists and giving them a sense of control: it’s a requirement if the algorithm is to learn from its mistakes and correct future errors.
This last point has two key challenges: how to design tools that allow for artist interaction, and how to enable ML networks to learn from and act on the feedback of those artists.
Most ML research to date removes the artist from the loop. If user interaction is included at all, it is limited.
As mentioned previously, it’s difficult to update ML algorithms in VFX tools due to the gap between research and deployment environments.
Feed-forward or inference-only ML models can’t easily capture updates natively within post-production software.
Bridging this gap is vital to developing the next generation of truly useful and artist-focused ML-based tools.
SmartROTO
As mentioned previously, one of Foundry’s new R&D projects, SmartROTO, aims to address some of the challenges we’ve looked at in this article.
Its aim is to investigate and design intelligent tools for high-end rotoscoping of live action footage.
The sharing of data sets is also a huge issue as we’ve discussed, so a significant part of the project will be dedicated to examining the sharing of machine learning networks and datasets.
Anybody familiar with the VFX industry will be aware of how time-consuming, manual and largely non-creative rotoscoping is. The tools developed in SmartROTO will use machine learning to create a step change in rotoscoping technology.
These new tools will minimize the interaction required by the rotoscoping artist, while retaining a familiar and intuitive user experience.
Ultimately, the aim is to bring significant savings to the VFX industry, a new plugin for Nuke, and new ways to share training datasets. Watch this space!